给手上的 RT-ACRH17 刷了梅林,然后实在是看那个 Double-NAT 不爽,打算把 Xfinity 的那个 modem 改成桥接模式。折腾一番之后终于搞定了,这里记录下几个问题。
我这个 modem 是 ARRIS TG1682G,型号是 XB3,调成桥接模式只要按照 Xfinity 的文档操作即可,调整完以后理论上只有 LAN1 可用,用一根网线从 modem 的 LAN1 直接接到 PC 上,看下通不通,如果通的话,说明 modem 本身没有问题,然后记录下 PC 有线网卡的 MAC 地址。
之后进入 RT-ACRH17 的设置界面,按照下图调整:
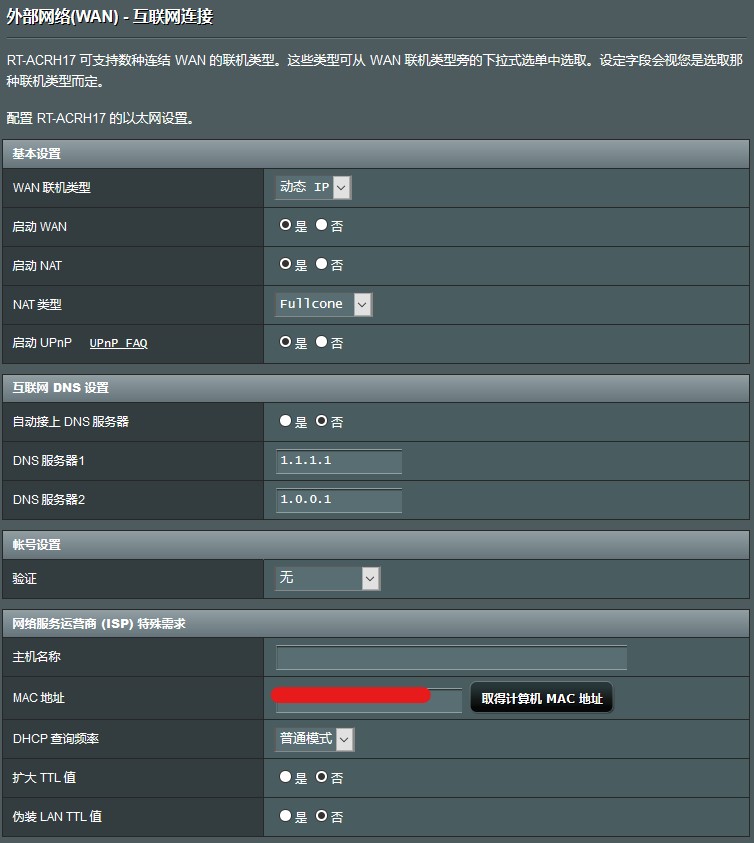
这里 DNS 我用的是 CloudFlare 的 public DNS,也可以换成例如 Google DNS 之类,这个无所谓。重点在于,在 ISP 特殊要求下,将 MAC 地址一栏中填入刚刚记下的 PC 有线网卡 MAC 地址,然后将 DHCP 查询频率改成普通。似乎 Xfinity 那里会限制这个 MAC 地址,如果不做克隆的话会无法完成 DHCP。也就是说,垃圾 Comcast 实际上是限制你用自己的无线路由的。
然后是 IPv6 的配置:
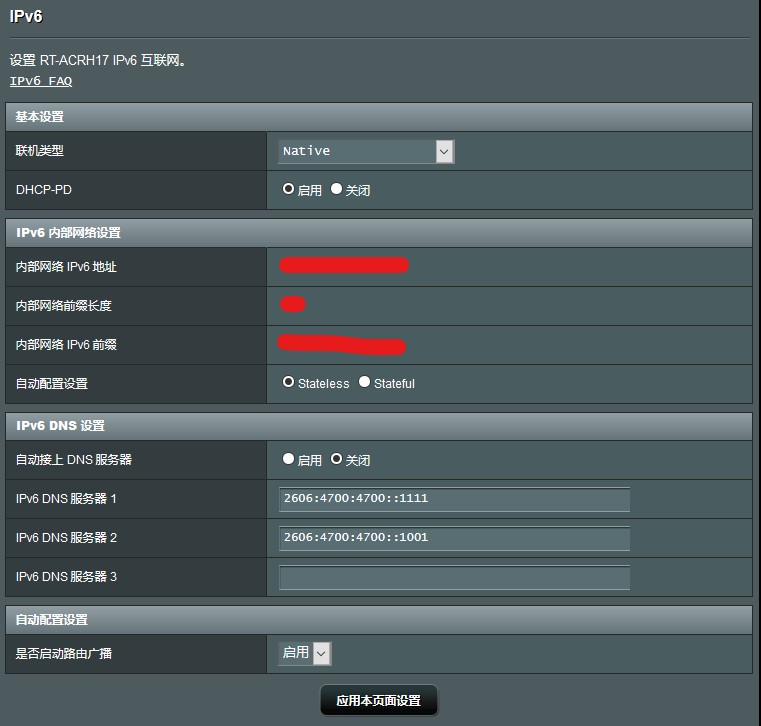
如果没有将 modem 改为桥接模式的话,这里类型应该选 Passthrough,在本文的场景下,应选择 Native,其他选项按照图内配置。同样的,这里的 DNS 我用的是 CloudFlare 的 DNS,可以改成其他你喜欢的地址。
稍等一段时间这里会出现一个 /64 的 prefix,说明配置成功。这里响应稍微有些慢,在 IPv4 上线以后可能还要两三分钟这里才会出现,是正常情况,等一下就好。
然后就结束了,重点就在于 MAC 地址要克隆 PC 的有线网卡地址,不然服务端会做一些奇怪的限制导致 DHCP 失败连不上网。