起因是这样的,美帝良心想这个 X1 Carbon 的官网上在调整 SSD 配置的时候,从 256G 加到 1T 需要增加 591USD,即使算上 45%off 的折扣也要 200 多刀。然而一个 SN750 1T 在美亚不过也才 200 刀,在官网加 SSD 就相当不合算了。
但是我注意到了一点,联想官网上对 SSD 的描述是 OPAL,也就是符合 OPAL 标准的自加密 SSD (Self-Encrypting Drive,SED),机器到手以后也默认开启了 BitLocker。在我的记忆中,BitLocker 是一个纯软件的实现,那么这里 SSD 的自加密和 BitLocker 的关系是什么呢?
查了一圈资料以后发现,BitLocker 存在硬件和软件两种实现方式。在检测到硬盘控制器支持硬件加密的时候,Windows 会直接使用该功能,且不对数据进行任何处理的方式就写入磁盘,由主控完成加密。如果主控不支持加密,则使用软件实现。具体的实现方式可以通过 manage-bde 这个命令查看:
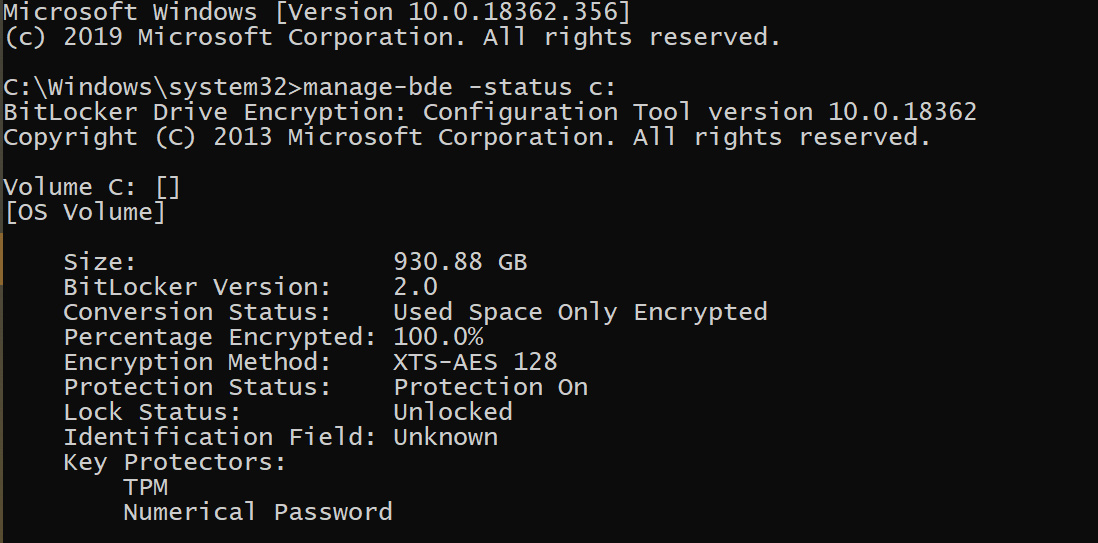 如果是软件实现,那么在 Encryption Method 下就会显示类似于 XTS-AES 128 这样的字眼。在一些比较老的版本上可能只是 AES 128。
如果是软件实现,那么在 Encryption Method 下就会显示类似于 XTS-AES 128 这样的字眼。在一些比较老的版本上可能只是 AES 128。
如果是启用了硬件加密特性,那么应该是这样:
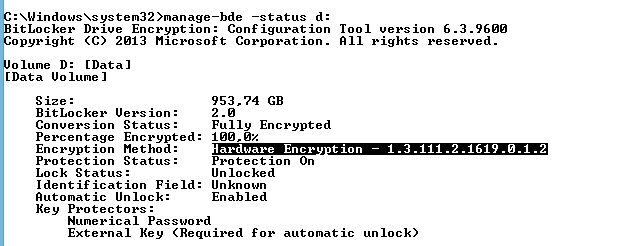 显示为 Hardware Encryption。
显示为 Hardware Encryption。
如果是官网购买的 OPAL Drive,那么应该是可以显示为 Hardware Encryption 的,如果是自行购买的 SN700(官网是 SN720,也就是前者的 OEM 版本),那么就是软件加密。
如果没有关闭 BitLocker 就取下了硬盘,在数据可以抹掉的情况下,理论上有两种方法可以解开。一个是使用 BitLocker 恢复密钥,这个会自动同步到自己的 Microsoft Account 上,可以看这里。或者也可以考虑直接使用命令抹掉数据并重新生成密钥,这个可以看 ArchWiki 的详细讲解。
Reference:
https://wiki.archlinux.org/index.php/Self-Encrypting_Drives
https://helgeklein.com/blog/2015/01/how-to-enable-bitlocker-hardware-encryption-with-ssd/
https://support.microsoft.com/en-us/help/4026181/windows-10-find-my-bitlocker-recovery-key
https://howtogeek.com/fyi/you-cant-trust-bitlocker-to-encrypt-your-ssd-on-windows-10/
https://portal.msrc.microsoft.com/en-US/security-guidance/advisory/ADV180028